
If Your Page Isn’t Indexed, Google Isn’t Ignoring You. It’s Judging You.
For years, indexing felt almost procedural. You published a page, waited a little, maybe nudged it through Google Search Console if you were impatient, and eventually Google would decide the page deserved a place in its index.
That confidence has weakened.
Lately, I’ve been seeing a familiar question surface across SEO communities, support forums, and Reddit threads: If a page isn’t indexed yet, can people still find it through Google Search?
The answers usually arrive quickly and bluntly. No index means no organic visibility. No visibility means no clicks from Google.
But after going through those discussions, what struck me wasn’t the consensus. It was the frustration around what happens before the answer.
Also read: How to Index Backlinks Faster
People are debating why pages that were indexed suddenly become “not indexed.” Site owners are comparing wildly different experiences. One person claims a new article was indexed in minutes. Another watches perfectly crawlable pages sit in limbo for weeks. Community operators, forum owners, and user-generated content sites sound especially uneasy, because indexing instability hits them harder than most.
The uncomfortable truth is that the simple answer — “not indexed means not searchable” — no longer explains enough.
The more useful question is: why is Google becoming so selective about what it keeps in its index?
That question matters more today than it did a few years ago because search itself is changing shape.
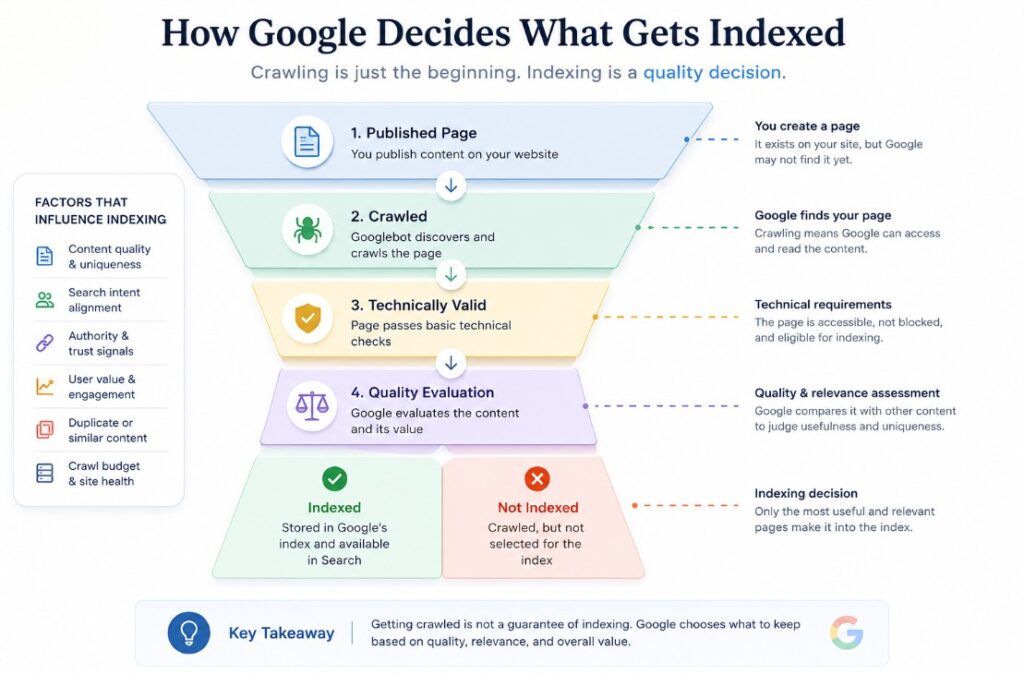
Google’s recent push toward AI-powered search experiences, AI Mode expansion, and more answer-driven search behavior has shifted attention away from the old “ten blue links” mindset. At the same time, Google continues to run broad ranking and quality updates that influence how content is evaluated, surfaced, and sometimes quietly excluded. Google’s own guidance has repeatedly emphasized helpfulness, reliability, and overall content value rather than mechanical SEO compliance. In practice, that often translates into a harder reality: getting crawled is not the same thing as getting accepted.
Many site owners still treat indexing like a technical checkbox.
It isn’t.
A page can be technically accessible, linked internally, present in a sitemap, free of robots blocks, and still fail to earn durable indexation. That feels unfair until you remember what Google’s index actually is: not a public archive of every published URL, but a curated working database of pages Google believes are worth retrieving and potentially showing.
That distinction explains something that confuses many publishers: pages do not merely fail to enter the index. They can also fall out of it.
And increasingly, they do.
Why Pages Get Dropped From Google’s Index
One of the stranger experiences in modern SEO is watching a page move backwards.
You publish a page. Google indexes it. Impressions begin to appear. You assume the hard part is over.
Then, without changing much, the page slips out of the index.
For newer site owners, this feels like a technical malfunction. For experienced publishers, it has become familiar enough to be irritating rather than shocking.
After spending time in SEO communities and Reddit discussions, I noticed a recurring pattern in how people explain this. Some immediately blame authority. Others point toward crawl issues, duplicate content, sitemap problems, or thin pages. The debates get messy because there is no single cause that explains every case.
Still, a few themes appear repeatedly.
The first is that Google has become more selective about content differentiation.
A technically sound page is not necessarily an index-worthy page. If your content looks interchangeable with dozens of similar URLs already available on the web, Google may crawl it without feeling compelled to retain it. This matters especially for category pages, templated location pages, AI-assisted content produced at scale, and large communities filled with short, repetitive user discussions.
That last category deserves attention.
Community sites and forums often assume that more content naturally strengthens SEO. Sometimes it does. Sometimes it creates a quality management problem disguised as growth.
Thousands of near-identical discussions, thin replies, empty profile pages, low-engagement threads, and weak archive URLs can dilute a site’s overall index quality. Google has hinted at this reality for years through discussions around helpful content, site quality systems, and large-scale content evaluation. In practical terms, a website can generate more URLs than Google believes are worth storing.
Authority also plays a role, although people often oversimplify it.
When someone says, “My new blog post got indexed in five minutes,” they are usually describing more than indexing speed. They are describing trust, crawl prioritization, internal linking maturity, historical performance, and Google’s existing confidence in the domain.
Meanwhile, a smaller site may submit a perfectly useful page and still wait days or weeks for a meaningful indexing decision.
That gap feels unfair until you remember that Google does not crawl the web democratically. It allocates attention.
There is another uncomfortable possibility that many publishers resist acknowledging.
Some pages are not dropped because something is broken. They are dropped because Google reevaluated their relative value.
That distinction matters.
If a page disappears from the index, the immediate instinct is often to hunt for technical defects. Sometimes that is correct. Broken canonicals, accidental noindex directives, crawl barriers, duplicate URL versions, and sitemap inconsistencies absolutely matter.
But many indexing problems today are qualitative before they are technical.
The question is not always, “Can Google access this page?”
Increasingly, the question is, “Why should Google keep this page when it already has thousands of alternatives?”
What I Would Actually Check Before Blaming Google
One thing became obvious after reading through recent Reddit threads, SEO forums, and publisher discussions. People rarely panic when a page takes an extra day to index. They panic when indexing behavior becomes inconsistent.
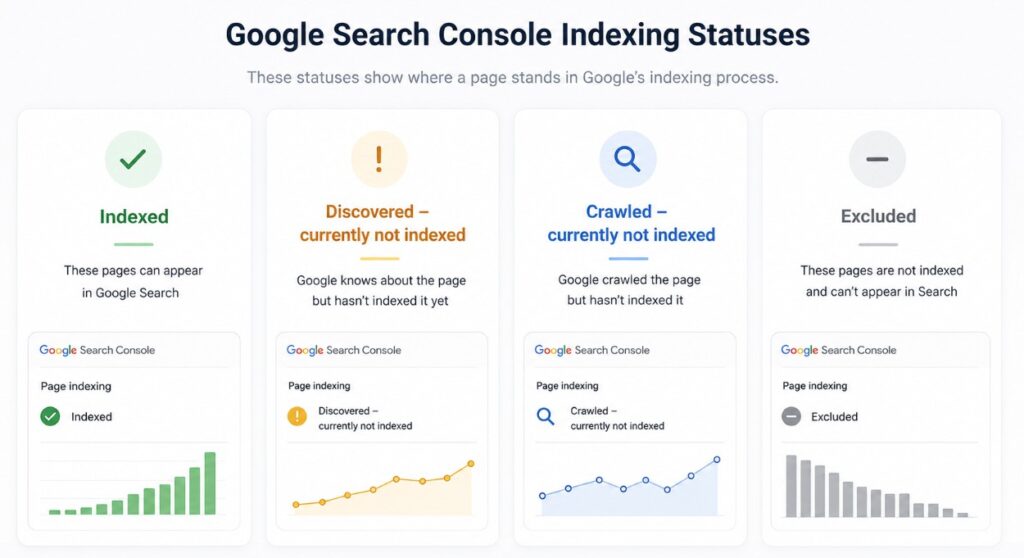
One article gets indexed almost immediately. Another, published on the same site with similar structure and comparable quality, sits in “Discovered” or “Crawled, currently not indexed” status with no clear explanation.
That inconsistency is what makes indexing feel mysterious.
In my experience, it helps to separate indexing checks into two buckets. The first bucket is technical eligibility. The second is perceived content value.
Start with the boring checks first.
Is the page actually included in your XML sitemap? Is it internally linked from meaningful pages, not buried five clicks deep? Are canonicals pointing where they should? Is there a stray no-index directive, parameter duplication issue, JavaScript rendering problem, or URL variant confusing Google?
These questions sound basic because they are. Yet they continue to surface in real indexing investigations.
But once the technical layer is reasonably clean, continuing to resubmit pages endlessly through Search Console usually produces diminishing returns.
At that point, I would look at the page through a harsher lens.
Does this page genuinely deserve independent existence?
That question sounds brutal, but it aligns surprisingly well with what many publishers are running into today.
If I compare a struggling page against one that consistently stays indexed, the differences are often subtle but meaningful. Stronger pages usually have clearer search intent alignment, more original utility, better information density, stronger contextual internal links, and a clearer reason for Google to retrieve them later.
Weak pages tend to feel replaceable.
That does not mean every page needs groundbreaking research or 3,000 words of expert commentary. It means the page should solve something specific better than a thin variation of content Google already understands.
For community sites, forums, and user-generated platforms, this becomes even more important.
Not every thread deserves indexation.
That may sound uncomfortable to operators who measure success through content volume, but recent search behavior increasingly rewards selective quality control. Low-value archives, empty discussions, duplicate topic variations, and near-abandoned threads can quietly consume crawl attention without contributing meaningful search value.
In some cases, pruning, consolidating, improving, or deliberately limiting indexation can be healthier than trying to force every URL into Google’s index.
That approach may feel counterintuitive in SEO circles that still equate “more indexed pages” with “better SEO.”
The web Google is evaluating today is noisier, more automated, more AI-assisted, and vastly more crowded than it was a few years ago.
Seen from that perspective, indexing delays and exclusions begin to look less like random punishment and more like aggressive filtering.
Also read: How to Buy Backlinks Safely and Without Destroying Rankings
The Real SEO Question Is Not “Will Google Index This?”
After spending time inside recent Reddit debates, publisher complaints, Search Console screenshots, and indexing discussions, I came away with a less dramatic but more useful conclusion.
Most indexing problems are not really about indexing.
They are about confidence.
Google is making a confidence decision about your page, your site structure, your content patterns, and increasingly, your ability to provide something worth storing in an index that does not need every page on the internet.
That does not mean site owners are powerless. It also does not mean every exclusion is deserved.
Google Search Console can still be frustratingly opaque. Pages can behave inconsistently. Strong content can wait longer than weaker content. Sometimes Google’s decisions genuinely feel difficult to defend from the outside.
But I think many publishers lose time asking the wrong question.
Instead of asking, “How do I force Google to index this page?” a more productive question might be: “What signals would make Google want to keep this page indexed?”
The difference matters.
One mindset treats indexing as a button that failed to work. The other treats indexing as an outcome that must be earned and maintained.
For publishers running communities, discussion sites, or large content ecosystems, that distinction is becoming harder to ignore. Search visibility is no longer just about publishing more pages, expanding topic coverage, or refreshing sitemaps every few hours.
It is about proving value at scale without drowning your own site in interchangeable URLs.
And yes, the original question still deserves a direct answer.
If your page is not indexed, people generally will not find it through Google Search.
But in 2026, that answer feels almost secondary.
The more important reality is that Google’s index is behaving less like a passive catalog and more like a selective editorial system. Whether you run a blog, a forum, a SaaS knowledge base, or a user-generated platform, adapting to that shift may matter more than any single indexing request you submit.